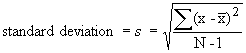
This collection of Pages concerning general undergraduate
biology curriculum reform has been organized by Susan Harrell and Monica
Beals under the supervision of Louis
Gross at the University of Tennessee,
Knoxville, with support from the National Science Foundation Undergraduate
Course and Curriculum Program through Award DUE-9752339, "Alternative Routes
to Quantitative Literacy for the Life Sciences".
Simple Statistics - mean, range, standard deviation
Definition of a Logarithmic Function
Formulas for Volume and Surface Area
Definition of a Linear Equation
Observers can collect data from a sample in order to make generalizations about a population. For example, we could collect data on height from a sample of college students in order to make generalizations about the entire population of college students. Certainly, there would be some degree of variability in the data we collected: certain heights would occur frequently, while others were less common. This could be due to natural variability in the population, as well as small differences in the way the data is collected between sampled individuals or by different observers. We can use statistics to describe, analyze, and interpret data in order to make generalizations about the sample and the population.
Descriptive statistics allows us to summarize important characteristics of collected data. Two important properties of a set of data are the central or typical value and the spread about that value. The central value is the value at the middle of a data set. Measures of central tendency include the mean, median, and mode. In our example, we could determine the typical height of students in our sample. The spread, or the degree of variation in a data set, is a measure of how far from the center value the data tend to range. In our example, if we had measured heights of many short and tall people, there would be a great deal of variation in the data. If we had only measured heights of individuals of very similar height, the spread would be much smaller. Measures of spread include the range and standard deviation.
The mean (`x), or average, is generally considered the most important descriptive measurement. It is obtained by adding all the data (x) and dividing by the number of observations (N):
mean = `x = (S x )/N
In our example, we would add all the heights we measured (x) and divide by the number of people we measured (N) in order to find the sample mean. The median of a data set is the middle value when scores are arranged in order of magnitude. If we arranged all the measured heights in increasing order, the median would be the middle value. The mode of a data set is the score that occurs most frequently. We could count the number of people having each particular height. The most common height would be the mode of the data set.
The spread or variation in a data set is a concept that is critical to many methods of statistics. The simplest way to measure spread is to compute the range, the difference between the highest and lowest value:
range = highest value - lowest value
The standard measure of spread is the standard deviation. It measures the spread from the mean and can be interpreted as the average distance of the data from the mean. If we have a particular data value, x, we can determine the deviation of that value from the mean by calculating the value of the data minus the mean, (x - ` x). Because we will get both positive and negative values, we could compensate for this by taking the absolute value of the deviations, | x - ` x|, so we get nonnegative values. The average deviation could then be described by adding all the deviations and then dividing by the number of observations (N). Instead of taking absolute values, however, a better measure of deviation is obtained by squaring the deviations, (x -` x)2, to make them nonnegative. We can then find the average squared deviation by adding all the squared deviations and, for technical reasons, dividing by the number of observations minus one (N -1). In order to compensate for the squared deviations, we must take the square root of the average deviation so our units are consistent. In summary, we can calculate the standard deviation as
The standard deviation has the same units as the original data. When the standard deviation is low, the spread around the mean is small. In such a case, the collected data would be quite similar to one another and to the mean. When the standard deviation is high, the spread around the mean is large. In this case, there is much greater variability in the collected data. For nearly symmetric, mound-shaped data sets, approximately 68% of the data is within one standard deviation of the mean and 95% is within two standard deviations of the mean. We could characterize a data value as unusual if it differs from the mean by more than 2 or 3 standard deviations (x > `x + 2s or x < `x - 2s).
Calculating descriptive statistics, such as the mean and standard deviation, for sampled data allows us to characterize the typical value and variability of a sample. Any conclusion an observer makes when comparing means of samples is greatly dependent on the variability within each sample. Generalizations about a population also depend on the mean and variability of the sampled data. Consequently, regardless of the observer's goal, the first step in characterizing or comparing populations is calculating descriptive statistics.
Example:
A student measures the doubling time (time for the number of cells to double by completing mitosis) for 5 cell samples grown in the presence of a growth factor. The doubling time for each cell sample, in hours, was 12.4, 10.5, 11.8, 13.6, and 14.5. The student wants to determine the mean doubling time and standard deviation for the cells.
mean = (12.4 + 10.5 + 11.8 + 13.6 + 14.5 )/5 = 12.6
standard deviation =
Ö [(12.4 - 12.6)2
+ (10.5 -12.6)2 + (11.8 - 12.6)2 + (13.6 - 12.6)2
+ (14.5 -12.6)2 ] / Ö
(5 - 1) = 1.6
T-test
Hypothesis testing involves using statistical properties of population means and standard deviations in order to determine the probability a hypothesis is true. We might look at the probability of getting a sample mean of`x, given that the population mean is m. This probability arises from the Central Limit Theorem: if we take several random samples of size N from a population, the distribution of sample means will approach a normal distribution for large sample sizes. Recall that for a normal distribution, about 95% of the sample means will fall within 2 standard deviations of the population mean. So only about 5% of the sample means will fall outside this interval. If the sample mean,`x, falls outside this interval, it would be unusual. In such a case, we would reject the hypothesis that the mean is m. This is the basic idea for using a t-test to compare the means of two populations.
The steps to hypothesis testing are 1) formulate hypotheses, 2) calculate the test statistic, 3) determine the p-value, and 4) compare the p-value to a fixed significance level, a. We can compare the means of two populations by using a t-test. Let`x1 , s1 and`x2 , s2 be the means and standard deviations of two samples of sizes N1 and N2 drawn from normally distributed populations with population means m1and m2and equal variances. The t-test is a statistical test of hypotheses that determines whether two samples are likely to have come from the same two underlying populations having the same mean.
Testing a statistical hypothesis involves deciding whether to accept the null hypothesis or reject it in favor of an alternate hypothesis. If we wish to compare two sample means, our hypotheses would be
Null hypothesis (H0) : m1=m2 or m1 - m2 = 0
Alternate hypothesis (HA) : m1¹ m2 or m1- m2¹ 0
We will be looking at the probability of getting sample means such that`x1¹`x2, given the null hypothesis is true - population means such that m1=m2.For large sample sizes (N > 30), we can assume a normal distribution and use the following test statistic:
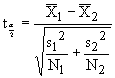
For small sample sizes (N < 30), the sample means follow a t-distribution rather than a normal distribution. We must pool the data from samples 1 and 2 to form a single estimate of the standard deviation. In this case, we use the test statistic
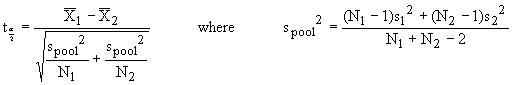
We can calculate the p-value to give us the probability of observing the test statistic (ta/2), given that the null hypothesis is true. We can look up the p-value in a table of the t-distribution for a two-tailed test for the absolute value of the t-statistic, |ta/2|. We generally pick a = 0.05 or 0.01. The degrees of freedom is given by N1 - N2 -2. For a = 0.05, we accept the null hypothesis if the probability of observing ta/2 is greater than a, or p > 0.05. We reject the null hypothesis in favor of the alternate hypothesis if p < 0.05. In such a case, obtaining a value of ta/2 for our sample is quite unusual (occurring for less than 5% of possible samples) if our null hypothesis is true, so we reject the null hypothesis.
Example:
A student measures the doubling time (time for
the number of cells to double by completing mitosis) for 5 cell samples
grown in the presence of a growth factor and 5 cell samples grown in the
absence of a growth factor.
|
|
|
|
|
Cell 1
|
|
|
|
Cell 2
|
|
|
|
Cell 3
|
|
|
|
Cell 4
|
|
|
|
Cell 5
|
|
|
|
Mean
|
|
|
|
Standard Deviation
|
|
|
The student notices that, although the means are different, there is some degree of overlap in the doubling time for cells grown in the presence or absence of a growth factor. The student wants to determine if the mean doubling times for cells grown in the presence or absence of a growth factor are significantly different.
Null hypothesis (H0) : mgf = mnotor mgf- mnot= 0
Alternate hypothesis (HA) : mgf ¹ mnot or mgf-mnot¹ 0
where mgf and mnotare the population means for cells grown in the presence or absence of a growth factor.
The student calculates the t-statistic for a small sample size (N = 5).

He looks up ta/2
in
a t-table for a
= 0.05, two-tailed test, and degrees of freedom = 8. In this case, p falls
between 0.05 and 0.02. The probability of obtaining the given t-statistic,
given that the null hypothesis is true, is quite small. Therefore, since
p < a, we reject
the null hypothesis in favor of the alternate hypothesis. The student concludes
that the mean doubling time of cells grown in the presence and absence
of a growth factor are significantly different at the level a
= 0.05.
| Property | Example | |
| 1 | aman = am+n | x2x4 = x6 |
| 2 | am/an = am-n | 25/23 = 25-3 = 22 |
| 3 | a-n = 1/an = (1/a)n | y-2 = 1/y2 = (1/y)2 |
| 4 | a0 = 1, a ¹ 0 | (x2 + 1)0 = 0 |
| 5 | (ab)m = ambm | (6x)2 = 62x2 = 36x2 |
| 6 | (am)n = amn | (y2)-3 = y-6 |
| 7 | (a/b)m = am/bm | (5/2)3 = 53/23 |
Definition of a Logarithmic Function
For x > 0 and 0 < a ¹ 1
y = logax if and only if ay = x
The function f(x) = logax is the logarithmic function with base a.
Formulas for Volume
and Surface Area
Circle
Area = pr2
Circumference = 2pr
Sphere
Volume = 4/3 pr3
Surface area = 4 pr2
Circular cylinder
Volume = pr2h
Surface area = 2prh + 2 pr2
where r is the radius and h is the height of the
cylinder.
A linear equation of y as a function of x is an equation that can be written in the standard form
y = mx + b
where m is the slope of the line and b is the y-intercept.
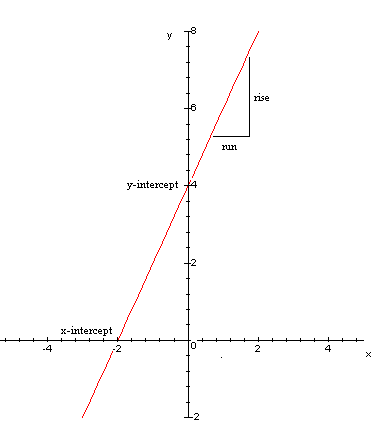
The slope of the line is the ratio of the rise to the run. The rise is the change in y and the run is the change in x. Hence, given 2 points (x1,y1), (x2,y2) on the line, we can describe the slope as
slope = m = (y2 - y1) / (x2 - x1)
The y-intercept is the point where the line hits
the y-axis and can be found by setting x = 0 and solving for y. The x-intercept
is the point where the line hits the x-axis and can be found by setting
y = 0 and solving for x.
Any set of paired observations (x,y) may be plotted on graph paper. The data may be highly scattered or may appear to follow a trend (such as a line or a curve). We can attempt to make sense of such data by fitting a straight line to it. If the y-values depend on the x-values, we can make predictions about which y-value will correspond with a given x by fitting a linear equation to the data. We can use linear regression to fit the best possible line to a set of data.
Note for a scatterplot of data, there are many possible lines that we could draw through the data. Each line would give us a new y' for a given value of x. This is given by the equation y' = mx + b. With each possible line, some of the data points (x, y) would lie closer or further from our drawn line (x, y'). The distance from data points to our drawn line is typically measured by drawing a vertical line from the data point to the drawn line and calculating the squared distance, d2 = (y' - y) 2. The method of least squares is used to find the best possible line. This method locates the line that minimizes the sum of the squared distances, Sd2 = S(y' - y)2.
To find the equation for the best possible line, y' = mx + b, we need to know the slope, m, and the y-intercept, b. We can find each of these by the method of least squares. The slope is given as
m = S (xy - N`x `y ) / S ( x2 - N`x2 )
where `x, `y are the mean of all the x-values and y-values, respectively, and N is the total number of paired observations (x, y). The slope may be positive or negative.
The best-fit line will pass through the mean of the x-values and y-values, in other words, the point (`x, `y ). Consequently, we can find the y-intercept, b, by substituting this point into the equation y' = mx + b and solving for b:
b = `y - m`x
Once we have fitted the straight line y' = mx + b to the data, we can predict which values of y will correspond to given values of x.
Notice we can fit a straight line to any set of paired data, even if the data are widely scattered or do not appear to fall in a straight line. We can determine how well the best-fit line explains the variability in the data by looking at r2, the ratio of the explained sum of squares to the total sum of squares:
r2 = S ( y' - `y )2 / S ( y - `y )2
where y is the original data y-value, y' is the
y-value predicted by the line, and`y
is the average of the y-values. The quantity r2 varies between
0 and 1 and describes the proportion of the variation in y that is predicted
from the variable x. Notice that if our data points (x, y) fall on or very
close to the predicted line y', then r2 will be very close to
1. If the data points are widely scattered, r2 will be closer
to 0.
Example
A student collects data on the dry weight of tomato
plants as the calcium content of the soil is increased.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
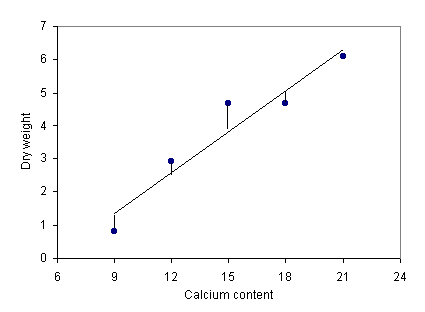
Upon graphing the data points, the student believes a straight line would fit the data well. The student finds the equation for the best line, y = mx + b, using the method of least squares. The slope is given as
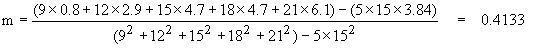
and the y-intercept is given as b = 3.84 - 0.4133*15 = -2.36
So the equation for the best line is given by y = 0.4133 x - 2.36
Using this equation, the student predicts that a calcium content of 14 mg/cm3 would result in a dry weight of y = 0.4133(14) - 2.36 = 3.43 grams.
The student also determines the r2 for the line. First, he calculates y' for each x-value in the data by substituting x into the equation y' = 0.4133x - 2.36 . For example, y'(9) = 0.4133´ 9 - 2.36 = 1.36. Then he calculates r2 as
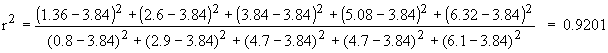
Therefore about 92% of the variation in plant
dry weight is explained by the calcium content of the soil.